The Calderon-Zygmund decomposition is a classic tool in harmonic analysis.
It’s also a part of a reframe of how I think since I started being immersed in this field.
The basic statement of the lemma is that all integrable functions can be decomposed into a “good” part, where the function is bounded by a small number, and a “bad” part, where the function can be large, but locally has average value zero; and we have a guarantee that the “bad” part is supported on a relatively small set.
Explicitly,
Let  and let
and let  . Then there exists a countable collection of disjoint cubes
. Then there exists a countable collection of disjoint cubes  such that for each $j$
such that for each $j$

(that is, the average value of f on the “bad” cubes is not too much bigger than  )
)

(that is, we have an upper bound on the size of the “bad” cubes)
and  for almost all x not in the union of the . In other words,
for almost all x not in the union of the . In other words,  is small outside the cubes, the total size of the cubes isn’t too big, and it’s not that big even on the cubes.
is small outside the cubes, the total size of the cubes isn’t too big, and it’s not that big even on the cubes.
In particular, if we define
 outside the cubes,
outside the cubes,  on each cube, and
on each cube, and  , then
, then 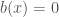 outside the cubes, and has average value zero on each cube. The “good” function
outside the cubes, and has average value zero on each cube. The “good” function 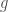 is bounded by ; the “bad” function
is bounded by ; the “bad” function  is only supported on the cubes, and has average value zero on those cubes.
is only supported on the cubes, and has average value zero on those cubes.
Why is this true? The basic sketch of the proof involves taking a big grid of cubes, asking on each one if the average of is less than or not; if not, the cube is a “bad” cube and we make it one of the , and if not, we keep subdividing, each cube being subdivided into 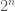 daughter cubes.
daughter cubes.
The intuition here is that functions which are more or less regular (an integrable function has to decay at infinity and not be too singular at zero) can be split into a “good” part that’s either small or locally constant, and a “bad” part that can be wiggly, but only on small regions, and always with average value zero on those regions.
This is the basic principle behind multiscale decompositions. You take a function on, say, the plane; you decompose it into a “gist” function which is constant on squares of size 1, and a “wiggle” function which is the difference. Then throw away the gist, look at the wiggle, look at squares of side-length 1/2, and again decompose it into a gist which is constant on squares and a wiggle which is everything else. And keep going. Your original function is going to be the sum of all the wiggles — or all the gists, depending on how you want to look at it.
But the nice thing about this is that you’re only using local information. To compute 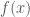 , you need to know what size-1 box
, you need to know what size-1 box  is in, for the first gist, and then which size-1/2 box, for the first wiggle, and then which size-1/4 box, for the second wiggle, and so on, but you only need to know the wiggles and gists in those boxes. And if the value of f changed outside the box, the decomposition and approximate value of wouldn’t change.
is in, for the first gist, and then which size-1/2 box, for the first wiggle, and then which size-1/4 box, for the second wiggle, and so on, but you only need to know the wiggles and gists in those boxes. And if the value of f changed outside the box, the decomposition and approximate value of wouldn’t change.
So how does this reframe how you see things in the real world?
Well, there are endless debates about whether you “can” capture a complex phenomenon with a simple model. Can human behavior “really” be reduced to an algorithm? Can you “really” describe economics or biology with equations? Is this the “right” definition to capture this idea?
To my view, that’s a wrong question. The right question is always “How much information do I lose by making this simplifying approximation?” A “natural” degree of roughness of your approximation is the turning point where more detail won’t give you much more accuracy.
Multiscale decompositions give you a way of thinking about the coarseness of approximations.
In regions where a function is almost constant, or varying slowly, one layer of approximation is pretty good. In regions where it fluctuates rapidly and at varying scales (think “more like a fractal”), you need more layers of approximation. A function that has rapid decay in its wavelet coefficients (the “wiggles” shrink quickly) can be approximated more coarsely than a function with slow decay. These are the functions where the “bad part” of the “bad part” of the “bad part” and so on (in the Calderon-Zygmund sense) remains fairly big rather than rapidly disappearing. (Of course, since the “bad part” is restricted to cubes, you can compute this separately in each cube, and require a different level of accuracy in different parts of the domain of the function.)
Definitions are approximations. You can define a category by its prototypical, average member, and then define subcategories by how they differ from that average, and sub-sub-categories by how they differ from the average of the sub-categories.
The hierarchical structure allows you to be much more efficient; you can skip the extra detail when it’s not warranted. In fact, there’s a fair amount of evidence that this is how the human brain structures information.
The language of harmonic analysis deals a lot with how to relate measures of regularity (basically, bounds on integrals, or measures of smoothness) with measures of coefficient decay (basically, how deep down the tree of successive approximations do you need to go to get a good estimate). Calderon-Zygmund decomposition is just one of the simpler cases. But the basic principle of “nicer functions permit rougher approximations” is a really good framing device to dissolve questions about choosing definitions and models. Debates about “this model can never capture all the complexity of the real thing” vs. “this model is a useful simplification” should be replaced by debates about how amenable the phenomenon is to approximation, and which model gives you the most accurate picture relative to its simplicity.

