
Post edited based on comments from Shea Levy, Daniel Speyer, Justin Alderis, and Andrew Rettek.
In the view of epistemology I’m putting forward in this sequence, the “best” way to construct a concept is the most useful way, relative to an agent’s goals. So, before we can talk about the question of “what makes a good concept?” we need to talk about evaluation.
Agents have values. Agents engage in goal-directed behavior; they have preferences; they have priorities; they have “utility functions”; etc. I’ll use these phrases more or less interchangeably. (I do not mean to claim that these “utility functions” necessarily obey Von Neumann-Morgenstern axioms.) What they mean is that an agent has a function over states of the world that captures how good each state of the world is, from the agent’s perspective. This function need not be single-valued, nor need every state of the world have a value. Humans may very well have complex, multi-dimensional values (we like things like pleasure, beauty, health, love, depth and challenge, etc).
Now, the natural question is, what is a state of the world? That depends on your ontology.
The “things” in your model of the world are concepts, as I described in the last post. Every concept is a generalization, over other concepts or over sensory perceptions; a concept is a collection of things that have a salient property in common, but differ in their irrelevant properties.
In neural net language, a concept is a non-leaf node in a (generalized) convolutional neural net. Pooling represents generalization; the lower nodes that feed into a given node on a pooling level are examples of the higher node, as in “dogs, snakes, and fish are all animals.” Composition represents, well, composition: the nodes on a composition level are composite concepts made up of the lower nodes that feed into them, as in “a unicorn is a horse with a horn on its forehead.”
So, what does this have to do with values?
In some states of the world, you have direct experiential perception of value judgments. Pleasure and pain are examples of value judgments. “Interestingness” or “surprisingness” are also value judgments; “incentive salience” (relevance to an organism’s survival) is one model of what sensations cause a spike in dopamine and attract an organism’s attention. (More on that in my past post on dopamine, perception, and values.)
Every value judgment that isn’t a direct experience must be constructed out of simpler concepts, via means such as inference, generalization, or composition. You directly experience being sick as unpleasant and being healthy as pleasant; you have to create the generalizations “sick” and “healthy” in order to understand that preference, and you have to model and predict how the world works in order to value, say, taking an aspirin when you have a headache.
Your value function is multivariate, and it may well be that some of the variables only apply to some kinds of concepts. It doesn’t make sense to ask how “virtuous” your coffee mug is. I’m deliberately leaving aside the question of whether some kinds of value judgments will be ranked as more important than others, or whether some kinds of value judgments can be built out of simpler kinds (e.g. are all value judgments “made of” pleasure and pain in various combinations?). For the moment, we’ll just think of value as (very) multivariate.
You can think of the convolutional network as a probabilistic graphical model, with each node as a random variable over “value”, and “child” nodes as being distributed according to functions which take “parent” nodes as parameters. So, for instance, if you have experiences of really enjoying playing with a cat, that gives you a probability distribution on the node “cat” of how much you like cats; and that in turn updates the posterior probability distribution over “animals.” If you like cats, you’re more likely to like animals. This is a kind of “taxonomic” inference.
Neural networks, in themselves, are not probabilistic; they obey rules without any reference to random variables. (Rules like “The parent node has value equal to the transfer function of the weighted sum of the child node values.”) But these rules can be interpreted probabilistically. (“The parent node value is a random variable, distributed as a logistic function of the child node variables.”) If you keep all the weights from the original neural net used to construct concepts, you can use it as a probabilistic graphical model to predict values.
Propagating data about values all over the agent’s ontology is a process of probabilistic inference. Information about values goes up to update the distributions of higher concepts, and then goes down to update the distributions of lower but unobserved concepts. (I.e. if you like kittens you’re more likely to like puppies.) The linked paper explains the junction tree algorithm, which indicates how to perform probabilistic inference in arbitrary graphs.
Of course, this kind of taxonomic inference isn’t the only way to make inferences. A lion on the other side of a fence is majestic; that lion becomes terrifying if he’s on the same side of the fence as you. You can’t make that distinction just by having a node for “lion” and a node for “fence.” And it would be horribly inefficient to have a node for “lion on this side of fence” and “lion on that side of fence”. What you do, of course, is value “survival”, and then predict which situation is more likely to kill you.
At present, I don’t know how this sort of future-prediction process could translate into neural-net language, but it’s at least plausible that it does, in human brains. For the moment, let’s black-box the process, and simply say that certain situations, represented by a combination of active nodes, can be assigned values, based on predictions of the results of those situations and how the agent would evaluate those results.
In other words, f(N_1, N_2, … N_k) = (v_1, v_2, … v_l), where the N’s are nodes activated by perceiving a situation, and the v’s are value assignments, and computing the function f may involve various kinds of inferences (taxonomic, logical, future-predicting, etc.) This computation is called teleological measurement.
The process of computing f is the process by which an agent makes an overall evaluation of how much it “likes” a situation. Various sense data produce immediate value judgments, but also those sensations are examples of concepts, and the agent may have an opinion on those concepts. You can feel unpleasantly cold in the swimming pool, but have a positive opinion of the concept of “exercise” and be glad that you are exercising. There are also logical inferences that can be drawn over concepts (if you go swimming, you can’t use that block of time to go hiking), and probabilistic predictions over concepts (if you swim in an outdoor pool, there’s a chance you’ll get rained on.) Each of these activates a different suite of nodes, which in turn may have value judgments attached to them. The overall, holistic assessment of the situation is not just the immediate pleasure and pain; it depends on the whole ontology.
After performing all these inferences, what you’re actually computing is a weighted sum of values over nodes. (The function f that determines the weights is complicated, since I’m not specifying how inference works.) But it can be considered as a kind of “inner product” between values and concepts, of the form
f(N) * V,
where V is a vector that represents the values on all the nodes in the whole graph of concepts, and f(N) represents how “active” each node is after all the inferences have been performed.
Note that this “weighted sum” structure will give extra “goodness points” to things that remain good in high generality. If “virtue” is good, and “generosity” is a virtue and also good, and “bringing your sick friend soup” is a species of generosity and also good, then if you bring your sick friend soup, you triple-count the goodness.
This is a desirable property, because we ordinarily think of things as better if they’re good in high generality. Actions are prudent if they continue to be a good idea in the long term, i.e. invariant over many time-slices. Actions are just if they continue to be a good idea no matter who does them to whom, i.e. invariant over many people. A lot of ethics involves seeking these kinds of “symmetry” or “invariance”; in other words, going to higher levels on the graph that represents your concept structure.
This seems to me to be a little related to the notion of Haar-like bases on trees. In the linked paper, a high-dimensional dataset is characterized by a hierarchical tree, where each node on the tree is a cluster of similar elements in the dataset. (Very much like our network of concepts, except that we don’t specify that it must be a tree.) Functions on the dataset can be represented by functions on the tree, and can be decomposed into weighted sums of “Haar-like functions” on the tree; these Haar-like functions are constant on nodes of a given depth in the tree and all their descendants. This gives a multiscale decomposition of functions on the dataset into functions on the “higher” nodes of the tree. “Similarity” between two data points is the inner product between their Haar-like expansions on the tree; two data points are more similar if they fall into the same categories. This has the same multiscale, “double-counting” phenomenon that shows up in teleological measurement, which gives extra weight to similarity when it’s not just shared at the “lowest” level but also shared at higher levels of generality.
(Haar-like bases aren’t a very good model for teleological measurement, because our function f is both multivariate and in general nonlinear, so the evaluation of a situation isn’t really decomposable into Haar functions. The situation in the paper is much simpler than ours.)
This gives us the beginning of a computational framework for how to talk about values. A person has a variety of values, some of which are sensed directly, some of which are “higher” or constructed with respect to more abstract concepts. Evaluating a whole situation or state of the world involves identifying which concepts are active and how much you value them, as well as inferring which additional concepts will be active (as logical, associational, or causal consequences of the situation) and how much you value them. Adding all of this up gives you a vector of values associated with the situation.
If you like, you can take a weighted sum of that vector to get a single number describing how much you like the situation overall; this is only possible if you have a hierarchy of values prioritizing which values are most important to you.
Once you can evaluate situations, you’re prepared to make decisions between them; you can optimize for the choices that best satisfy your values.
An important thing to note is that, in this system, values are relative to the agent’s ontology. Values are functions on your neural network; they aren’t applicable to some different neural network. Values are personal; they are only shared between agents to the extent that the agents have a world-model in common. Disagreement on values is only possible when an ontology is shared. If I prioritize X more than you do, then we disagree on values; if you have no concept of X then we don’t really disagree, we’re just seeing the world in alien ways.
Now that we have a concrete notion of how values work, we can go on to look at how an agent chooses “good” concepts and “good” actions, relative to its values, and what to do about ontological changes.
Note: terms in bold are from ItOE; quantitative interpretations are my own. I make no claims that this is the only philosophical language that gets the job done. “There are many like it, but this one is mine.”
 and let
and let  . Then there exists a countable collection of disjoint cubes
. Then there exists a countable collection of disjoint cubes  such that for each $j$
such that for each $j$
 )
)
 for almost all x not in the union of the
for almost all x not in the union of the  is small outside the cubes, the total size of the cubes isn’t too big, and it’s not that big even on the cubes.
is small outside the cubes, the total size of the cubes isn’t too big, and it’s not that big even on the cubes. outside the cubes,
outside the cubes,  on each cube, and
on each cube, and  , then
, then 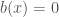 outside the cubes, and has average value zero on each cube. The “good” function
outside the cubes, and has average value zero on each cube. The “good” function 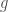 is bounded by
is bounded by  is only supported on the cubes, and has average value zero on those cubes.
is only supported on the cubes, and has average value zero on those cubes.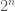 daughter cubes.
daughter cubes.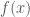 , you need to know what size-1 box
, you need to know what size-1 box  is in, for the first gist, and then which size-1/2 box, for the first wiggle, and then which size-1/4 box, for the second wiggle, and so on, but you only need to know the wiggles and gists in those boxes. And if the value of f changed outside the box, the decomposition and approximate value of
is in, for the first gist, and then which size-1/2 box, for the first wiggle, and then which size-1/4 box, for the second wiggle, and so on, but you only need to know the wiggles and gists in those boxes. And if the value of f changed outside the box, the decomposition and approximate value of 